L’algorithme des k plus proches voisins est un algorithme qui, à partir d’un jeu de données et d’une donnée « cible », détermine les k données les plus proches de la cible.
I. Algorithme naïf
Voici un algorithme qui permet de résoudre le problème.
Données :
• une table de données de taille n : table ;
• une donnée cible : cible ;
• un entier k plus petit que n ;
• une règle permettant de calculer la « distance » entre deux données.
Résultat : les k plus proches voisins de la cible ;
Algorithme :
1. Trier les données de la table selon la distance croissante avec la donnée cible.
2. proches_voisin est la liste des k premières données de la table triée.
3. Renvoyer proches_voisins.
II. Implémentation en Python
On suppose donnée une fonction distance qui calcule la distance entre deux données. On peut alors implémenter en Python de la façon suivante :

III. Choix de la distance
Le choix du mode de calcul de la distance entre deux données n’est pas anodin. En voici l’illustration avec un échantillon de 10 données (points bleu) et d’une cible (point rouge).
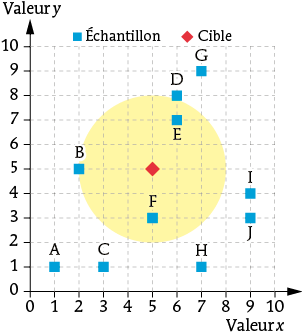
En utilisant la distance « naturelle », c’est-à-dire celle qui est donnée par une règle graduée, les trois plus proches voisins de la cible sont les points B, E et F. Dans un repère orthonormé, cette distance est donnée par la formule :
distance(point1,point2)=(x1−x2)2+(y1−y2)2.
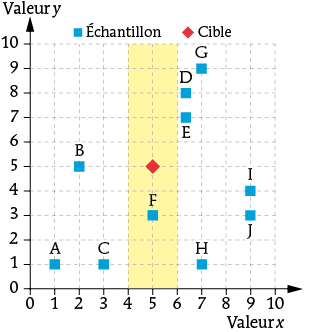
Si maintenant on considère que les valeurs sur l’axe des ordonnées n’ont pas d’intérêt, on utilise une distance qui ne dépend pas de y, par exemple :
À noter
Dans la, vous trouverez trois exemples de calcul de distance.
distance(point1, point2)=|x1−x2|.
Dans ce cas, les trois plus proches voisins de la cible sont les points D, E et F.