
L’information portée par l’ARNm est traduite en une suite d’acides aminés (protéine) à l’aide du code génétique.
I. Le code génétique
Mot clé
Transgenèse : technique consistant en un transfert de gène d’un organisme à un autre (de la même espèce ou non).
Le code génétique est un code de correspondance entre un codon (triplet de nucléotides) et un acide aminé. Il possède plusieurs propriétés, il est : univoque (chaque codon ne correspond qu’à un seul acide aminé), redondant (des codons différents peuvent coder le même acide aminé), universel (la plupart des êtres vivants utilisent ce même code lors de la synthèse des protéines).
La transgenèse s’appuie sur l’universalité du code génétique : le transgène est à l’origine de la même protéine chez l’organisme récepteur et donneur.
Il ne faut pas confondre code et information. L’information nécessaire à la synthèse d’une protéine correspond à la suite de nucléotides portée par un gène sur la molécule d’ADN (et l’ARNm correspondant). Le code génétique (cf. exercice 5) est un outil qui permet de décoder cette information, pour la convertir en une suite d’acides aminés (protéine).
II. Les étapes de la traduction
La traduction est réalisée dans le cytoplasme par des ribosomes, suivant l’ordre imposé par la séquence de l’ARNm. Elle s’effectue en trois étapes :
- initiation : le ribosome se fixe sur le codon initiateur et place la méthionine ;
- élongation : le ribosome se déplace de codon en codon et lie les acides aminés entre eux en respectant le code génétique ; la protéine s’agrandit ;
- terminaison : lorsque le ribosome rencontre un codon stop, il se détache de l’ARNm et la traduction s’arrête. La méthionine est enlevée et la protéine acquiert sa forme tridimensionnelle.
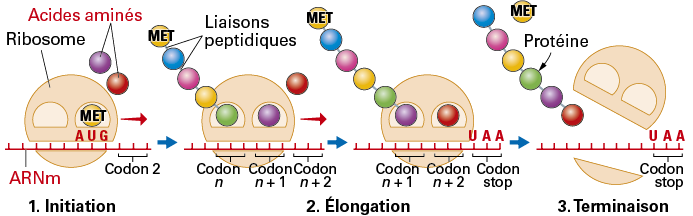
Doc Étapes de la traduction
Méthode
Calculer un nombre de combinaisons possibles
Les protéines sont formées d’une succession d’acides aminés déterminée par la séquence de nucléotides de l’ARNm qui les code. Cette correspondance entre l’information codée par une suite de 4 nucléotides différents et la séquence protéique composée de 20 types d’acides aminés, a des similitudes avec l’information présente dans les programmes informatiques, dont certains sont codés par une suite binaire (chiffres 0 ou 1).
Chaque objet porteur d’une information (gène, ARN, protéine, programme informatique) peut exister en de nombreuses versions, dépendantes de la taille de la séquence et du nombre de différents éléments qui la composent.
Calculer le nombre de séquences différentes possibles pour un gène composé d’une suite de 2, 5 ou 10 nucléotides. Faire de même avec une protéine composée du même nombre d’acides aminés, et comparer avec un programme informatique codé de manière binaire.
>Conseils
Étape 1 Pour chaque objet, repérer le nombre de différents éléments (nucléotide, acide aminé, chiffres…) qui le composent.
Étape 2 Appliquer la formule mathématique correspondante :
nombre de combinaisons possibles = en, avec e le nombre d’éléments différents dans la séquence et n la taille de la séquence.
Étape 3 Présenter les résultats dans un tableau pour les comparer facilement.
Solution
Étape 1 Un gène est constitué de 4 types de nucléotides, une protéine de 20 types d’acides aminés, un programme informatique de 2 types de chiffres.
Étape 2 Pour un gène de 5 nucléotides de long, il y a 45 = 1 024 séquences possibles. Pour une protéine de 5 acides aminés : 205 = 3,2 × 106 séquences possibles. Pour un programme informatique : 25 = 32 séquences possibles.
Étape 3 Comparaison du nombre de séquences possibles.
|
Taille de la séquence |
Programme informatique |
Gène |
Protéine |
|
2 |
4 |
16 |
400 |
|
5 |
32 |
1 024 |
3,2 × 106 |
|
10 |
1 024 |
1 048 576 |
1,024 × 1013 |
À noter
La taille moyenne d’un gène humain est de 27 000 nucléotides, celle d’une protéine de plusieurs centaines d’acides aminés : le nombre de combinaisons possibles est donc immense !