
L’apprentissage automatique, inventé par Arthur Samuel en 1959, est aujourd’hui exploité par une vaste majorité d’IA. L’arrivée du big data a permis de développer encore plus son potentiel.
I. Les modes d’apprentissage automatique
1) Principales méthodes d’apprentissage
Il existe trois grandes méthodes d’apprentissage, toutes basées sur des principes de statistiques et de probabilités, et nécessitant un grand nombre de données (big data).
Mot-clé
Le big data désigne un ensemble de données si volumineux qu’il dépasse les capacités humaines d’analyse ainsi que celles des outils classiques de gestion de données.
L’apprentissage supervisé : apprentissage à partir d’un grand nombre d’exemples où on donne à la machine les données d’entrée ET le résultat attendu. Par exemple, en fournissant des milliers de photos de chats à la machine, elle finira par reconnaître des chats dans un jeu d’images.
L’apprentissage non supervisé, encore balbutiant : apprentissage prédictif dans lequel la machine va « découvrir » les données d’entrée, émettre des « hypothèses » et les vérifier au fur et à mesure.
L’apprentissage par renforcement : le programme va progresser par essais et erreurs successifs, en posant une entrée et en testant les sorties possibles.
2) Le deep learning et les réseaux de neurones
Le deep learning est un système d’apprentissage qui s’appuie sur des réseaux de neurones artificiels pour en démultiplier l’efficacité.
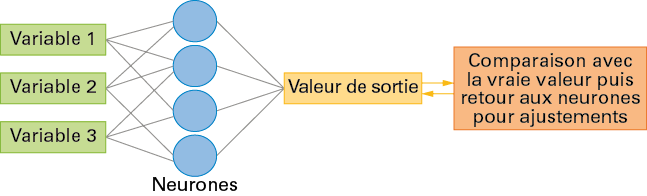
Un réseau de neurones artificiels est un ensemble d’algorithmes qui vont fonctionner comme des neurones formels, c’est-à-dire des représentations mathématiques du fonctionnement d’un neurone biologique. Un tel neurone possède plusieurs entrées et une sortie.
Doc 1 Schéma simplifié d’un réseau de neurones
II. Les inférences bayésiennes et la mémorisation
La méthode d’inférence bayésienne permet de calculer les probabilités de causes à partir de l’observation d’évènements connus. La probabilité correspond au degré de confiance à accorder à une cause hypothétique. Dans le cas d’un réseau de neurones, ceux-ci vont alors renforcer le poids des causes les plus probables dans leurs calculs et délaisser celles qui paraissent improbables, un peu comme le ferait un neurone biologique en renforçant les connexions les plus efficaces et utiles.
Cette méthode se base sur le théorème de Bayes ; si A et B sont deux événements relatifs à la même expérience, alors :
PBA=PA(B)×PAPB
où PB(A) est la probabilité conditionnelle de A sachant B, c’est-à-dire la probabilité que A soit réalisé sachant que B est réalisé.
Cette technique va trouver un intérêt particulier pour effectuer des diagnostics (médicaux ou industriels), modéliser les risques, détecter les spams ou même faire du data mining.
Mot-clé
Le data mining, aussi appelé « exploration », consiste à utiliser des techniques automatiques ou semi-automatiques pour extraire des connaissances à partir de quantités massives de données.